lidar摄像头融合
A novel approach for fusing LIDAR and visual camera images in unstructured environment
B. Yohannan and D. A. Chandy, “A novel approach for fusing LIDAR and visual camera images in unstructured environment,” 2017 4th International Conference on Advanced Computing and Communication Systems (ICACCS), Coimbatore, India, 2017, pp. 1-5, doi: 10.1109/ICACCS.2017.8014604.
Abstract: Image fusion is the process of merging all similar information from two or more images into a single image. The aim is to provide an image fusion method for fusing the images from the different modalities so that the fusion image will give more information without losing input information and also without any redundancy. This paper gives the efficient method for fusion purpose, by fusing LIDAR and visual camera images. The objective of this proposed method is to develop an image fusion algorithm and its applications in automated navigation in an unstructured environment.
图像融合是将来自两个或更多图像的所有相似信息合并为一个图像的过程。目的是提供一种用于融合来自不同模态的图像的图像融合方法,使得融合图像将给出更多的信息而不会丢失输入信息,并且也没有任何冗余。通过融合激光雷达图像和摄像机图像,给出了一种有效的融合方法。该方法的目的是开发一种图像融合算法及其在非结构化环境中的自动导航中的应用。
keywords: {Cameras;Laser radar;Image fusion;Image edge detection;Visualization;Sensors;Communication systems;Image fusion;Edge detection;Background removal;LIDAR;Ford campus vision}
URL: https://ieeexplore.ieee.org/stamp/stamp.jsp?tp=&arnumber=8014604&isnumber=8014556
主要采用全方位摄像机(5个摄像头)与lidar(该lidar能够直接出图),基本步骤为:
- 图像采集
- 将两种图片均转为灰度图片
- 边缘检测
- 删除背景
- 调整图像大小并旋转图像
融合结果如下:

对硬件要求比较高,融合简单粗暴,直接通过图像叠加实现,整篇文章的重点在检测出边缘后将天空等无用背景删除,因为lidar成像是不包括天空的
Sensor Fusion of a Camera and 2D LIDAR for Lane Detection
Y. Yenıaydin and K. W. Schmidt, “Sensor Fusion of a Camera and 2D LIDAR for Lane Detection,” 2019 27th Signal Processing and Communications Applications Conference (SIU), Sivas, Turkey, 2019, pp. 1-4, doi: 10.1109/SIU.2019.8806579.
Abstract: This paper presents a novel lane detection algorithm based on fusion of camera and 2D LIDAR data. On the one hand, objects on the road are detected via 2D LIDAR. On the other hand, binary bird’s eye view (BEV) images are acquired from the camera data and the locations of objects detected by LIDAR are estimated on the BEV image. In order to remove the noise generated by objects on the BEV, a modified BEV image is obtained, where pixels occluded by the detected objects are turned into background pixels. Then, lane detection is performed on the modified BEV image. Computational and experimental evaluations show that the proposed method significantly increases the lane detection accuracy.
本文提出了一种基于摄像机和二维激光雷达数据融合的新型车道检测算法。一方面,通过2D LIDAR检测道路上的物体。另一方面,从照相机数据获取二元鸟瞰图(BEV)图像,并在BEV图像上估计由LIDAR检测到的物体的位置。为了消除由BEV上的物体产生的噪声,获得了修改后的BEV图像,在该图像中,被检测到的物体所遮挡的像素被转换为背景像素。然后,对修改后的BEV图像执行车道检测。计算和实验评估表明,该方法大大提高了车道检测的准确性。
keywords: {Laser radar;Cameras;Two dimensional displays;Roads;Image segmentation;Feature extraction;Transforms;2D LIDAR;camera;lane detection;modified bird’s eye view;sensor fusion}
URL: https://ieeexplore.ieee.org/stamp/stamp.jsp?tp=&arnumber=8806579&isnumber=8806230
这篇论文主要是通过lidar排除摄像头在识别车道线时一些外界的干扰,因为在有些时候车道线可能会被前方车辆挡住,此时通过摄像头获取的结果就会有前车的干扰。其基本思路如下:
-
从摄像头和lidar上获取原始数据,假设摄像头上获取的直接是二元鸟瞰图(BEV)图像
-
将lidar上的点进行聚类,并将lidar上的点通过下式映射到摄像头图像上
\begin{equation*} P^{c}=RP^{l}+t \tag{1} \end{equation*} \begin{equation*} \gamma\cdot[u\ v\ 1]^{T}=HK(RP^{l}+t) \tag{2} \end{equation*} -
标出lidar对象的矩形,再通过摄像头和矩形的连线确定背景区域,然后直接删除该部分区域进行后续车道线识别
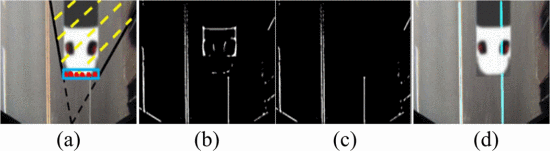
-
最终结果:
式子1中旋转矩阵R和变换向量t的获取可以参考以下论文
- L. Zhou and Z. Deng, “Extrinsic calibration of a camera and a lidar based on decoupling the rotation from translation”, IEEE Intelligent Vehicles Symposium (□), pp. 642-648, 2012.
- Z. Lipu and Z. Deng, “A new algorithm for extrinsic calibration of a 2D LIDAR and a camera”, Measurement Science and Technology, vol. 25, no. 6, 2014.
优点:硬件简单,仅仅利用一个二维lidar+普通摄像头,本文还考虑到了lidar识别的高度在摄像头成像中的偏差,并且最后进行了纠正
An advanced object classification strategy using YOLO through camera and LiDAR sensor fusion
J. Kim, J. Kim and J. Cho, “An advanced object classification strategy using YOLO through camera and LiDAR sensor fusion,” 2019 13th International Conference on Signal Processing and Communication Systems (ICSPCS), Gold Coast, QLD, Australia, 2019, pp. 1-5, doi: 10.1109/ICSPCS47537.2019.9008742.
Abstract: In this paper, we propose weighted-mean YOLO to improve real-time performance of object detection by fusing information of RGB camera and LIDAR. RGB camera is vulnerable to external environments and therefore strongly affected by illumination. Conversely, LIDAR is robust to external environments, but has low resolution. Since each sensor can complement their disadvantages, we propose a method to improve the performance of object detection through sensor fusion. We design the system using weighted-mean to construct a robust system and compared with other algorithms, it shows performance improvement of missed-detection.
在本文中,我们提出了加权平均YOLO,通过融合RGB摄像机和LIDAR的信息来提高物体检测的实时性能。 RGB相机易受外部环境影响,因此会受到照明的强烈影响。相反,激光雷达对外部环境具有鲁棒性,但分辨率较低。由于每个传感器都可以弥补其缺点,因此我们提出了一种通过传感器融合来提高目标检测性能的方法。我们使用加权均值设计系统,以构建一个健壮的系统,并与其他算法进行比较,它显示出漏检性能的提高。
keywords: {Object detection;Cameras;Laser radar;Feature extraction;Reflectivity;Sensor fusion;Three-dimensional displays;YOLO;real-time;object detection;sensor fusion;LIDAR}
URL: https://ieeexplore.ieee.org/stamp/stamp.jsp?tp=&arnumber=9008742&isnumber=9008412
术语:
- PCD(Point Cloud Data):点云数据
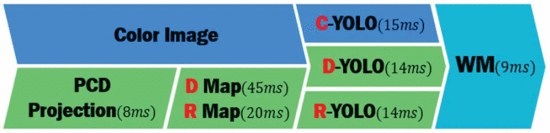
整篇论文的基本框图如下所示:
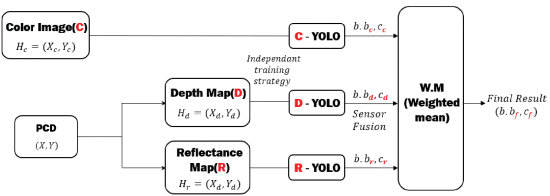
文章直接使用的Kim数据集,其中用的lidar所采集的数据格式为,其中r为信号的反射强度。文章首先将3D点云投射到摄像头采集的图像上,然后将其分离为深度图和反射强度图。再先后将三种图分别通过三个YOLO网络,每个网络得到一个物体边界信息b和种类概率信息c,然后通过加权每个图的概率c,得到:
\begin{align*}b.b_{f}=\left(\displaystyle \frac{\Sigma_{k}x_{k^{C}k}}{\Sigma_{k}c_{k}},\displaystyle \frac{\Sigma_{k}y_{k^{C}k}}{\Sigma_{k}c_{k}},\displaystyle \frac{\Sigma_{k}w_{k^{C}k}}{\Sigma_{k}c_{k}},\displaystyle \frac{\Sigma_{k}h_{k}c_{k}}{\Sigma_{k}c_{k}}\right) \tag{3}\end{align*}整个模型在PC上跑,平均总共耗时77ms,其他时间如下:
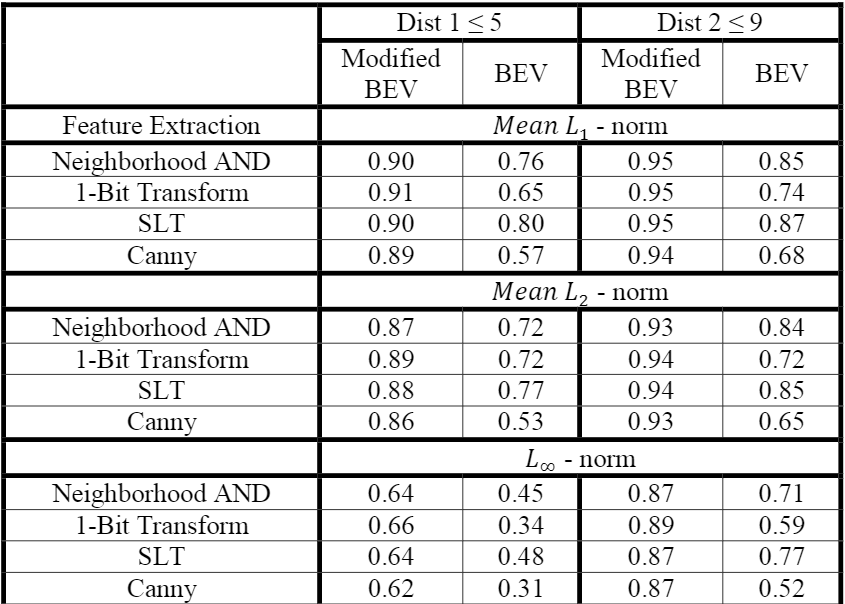
前三个网络以及加上WM-YOLO网络的精度如下:
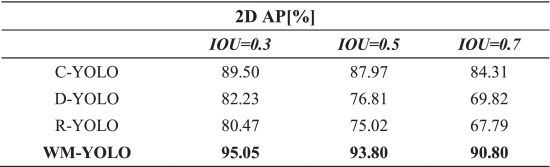
整篇论文的核心就是上述WM-YOLO网络,其实就是做了个简单的加权,但是通过最后结果观察效果却好很多
Robust Vision-Based Relative-Localization Approach Using an RGB-Depth Camera and LiDAR Sensor Fusion
H. Song, W. Choi and H. Kim, “Robust Vision-Based Relative-Localization Approach Using an RGB-Depth Camera and LiDAR Sensor Fusion,” in IEEE Transactions on Industrial Electronics, vol. 63, no. 6, pp. 3725-3736, June 2016, doi: 10.1109/TIE.2016.2521346.
Abstract: This paper describes a robust vision-based relative-localization approach for a moving target based on an RGB-depth (RGB-D) camera and sensor measurements from two-dimensional (2-D) light detection and ranging (LiDAR). With the proposed approach, a target’s three-dimensional (3-D) and 2-D position information is measured with an RGB-D camera and LiDAR sensor, respectively, to find the location of a target by incorporating visual-tracking algorithms, depth information of the structured light sensor, and a low-level vision-LiDAR fusion algorithm, e.g., extrinsic calibration. To produce 2-D location measurements, both visual- and depth-tracking approaches are introduced, utilizing an adaptive color-based particle filter (ACPF) (for visual tracking) and an interacting multiple-model (IMM) estimator with intermittent observations from depth-image segmentation (for depth image tracking). The 2-D LiDAR data enhance location measurements by replacing results from both visual and depth tracking; through this procedure, multiple LiDAR location measurements for a target are generated. To deal with these multiple-location measurements, we propose a modified track-to-track fusion scheme. The proposed approach shows robust localization results, even when one of the trackers fails. The proposed approach was compared to position data from a Vicon motion-capture system as the ground truth. The results of this evaluation demonstrate the superiority and robustness of the proposed approach.
本文介绍了基于RGB深度(RGB-D)相机和来自二维(2-D)光检测和测距(LiDAR)的传感器测量结果的,基于运动的目标的基于视觉的鲁棒相对定位方法。通过提出的方法,分别使用RGB-D相机和LiDAR传感器测量目标的三维(3-D)和2-D位置信息,以通过结合视觉跟踪算法,深度来找到目标的位置结构化光传感器的信息以及低级视觉-LiDAR融合算法(例如,外部校准)。为了产生二维位置测量,引入了视觉跟踪和深度跟踪方法,利用自适应的基于颜色的粒子滤波(ACPF)(用于视觉跟踪)和交互的多模型(IMM)估计器以及来自深度的间歇性观察-图像分割(用于深度图像跟踪)。二维LiDAR数据通过替换视觉和深度跟踪的结果来增强位置测量;通过此过程,将生成目标的多个LiDAR位置测量值。为了处理这些多位置测量,我们提出了一种改进的轨道间融合方案。所提出的方法显示出鲁棒的定位结果,即使其中一个跟踪器发生故障也是如此。将拟议的方法与来自Vicon运动捕捉系统的位置数据作了比较,作为基本事实。评估结果证明了该方法的优越性和鲁棒性。
keywords: {Laser radar;Cameras;Target tracking;Robustness;Robot sensing systems;Calibration;Localization;RGB-D camera;LiDAR;Visual tracking;Depth segmentation;Intermittent observation;Interacting multiple Model;Modified track to track fusion;Depth segmentation;interacting multiple model (IMM);intermittent observation;light detection and ranging (LiDAR);localization;modified track-to-track fusion;RGB-depth (RGB-D) camera;visual tracking}
URL: https://ieeexplore.ieee.org/stamp/stamp.jsp?tp=&arnumber=7390258&isnumber=7467584
本文首先通过使用外在校准算法将摄像头和lidar进行低级融合,然后通过一个视觉跟踪器和一个深度跟踪器选择一个ROI,并对此区域进行精确测量,最后提出一种改进的轨道间融合的算法进行本地化的融合
整篇论文首先是通过使用视觉跟踪+lidar,结果发现效果不是很好,进而改用深度跟踪+lidar。其中深度跟踪算法这块是整篇论文的核心。
RoIFusion: 3D Object Detection from LiDAR and Vision
When localizing and detecting 3D objects for autonomous driving scenes, obtaining information from multiple sensor (e.g. camera, LIDAR) typically increases the robustness of 3D detectors. However, the efficient and effective fusion of different features captured from LIDAR and camera is still challenging, especially due to the sparsity and irregularity of point cloud distributions. This notwithstanding, point clouds offer useful complementary information. In this paper, we would like to leverage the advantages of LIDAR and camera sensors by proposing a deep neural network architecture for the fusion and the efficient detection of 3D objects by identifying their corresponding 3D bounding boxes with orientation. In order to achieve this task, instead of densely combining the point-wise feature of the point cloud and the related pixel features, we propose a novel fusion algorithm by projecting a set of 3D Region of Interests (RoIs) from the point clouds to the 2D RoIs of the corresponding the images. Finally, we demonstrate that our deep fusion approach achieves state-of-the-art performance on the KITTI 3D object detection challenging benchmark.
本文采用KITTI数据集进行测试,通过设计出一个轻量级的RolFusion网络来解决融合问题:其主要由一个关键点生成层提取估计对象上的关键点,再通过一个投票层产生对象的中心点,并根据该中心点生成一个三维ROI,最后通过RolFusion层将生成的三维ROI与对应的二维ROI进行融合
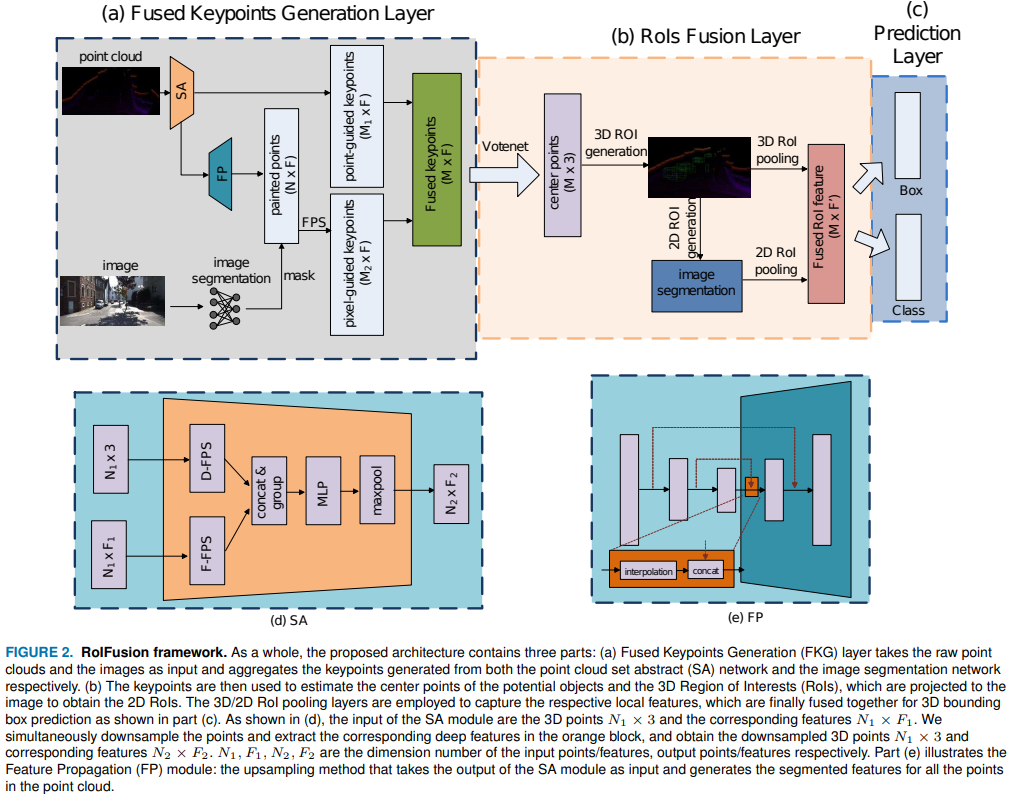
该文章通过lidar数据来计算ROI从而达到筛选有用数据的目的,从而避免了大量的冗余计算,和第二篇文章有点异曲同工


